CVE¶
Common Vulnerabilities and Exposures Identifier (CVE ID) is a unique, alphanumeric identifier assigned by the CVE Program. Each identifier references a specific vulnerability. A CVE ID enables automation and multiple parties to discuss, share, and correlate information about a specific vulnerability, knowing they are referring to the same thing
source: www.cve.org
You can see this notebook directly via:
Generation time¶
[1]:
from datetime import datetime, timezone, timedelta
timezone_offset = 0.0
tzinfo = timezone(timedelta(hours=timezone_offset))
generation_time = datetime.now(tzinfo).strftime('%Y-%m-%d %H:%M:%S %z')
print(generation_time)
2026-05-10 16:57:43 +0000
Creative Commons¶
This notebook and generated diagrams are released with Creative Commons liecense (CC BY 4.0).

[2]:
import requests
import urllib3
urllib3.disable_warnings()
urls = ['https://mirrors.creativecommons.org/presskit/icons/cc.xlarge.png',
'https://mirrors.creativecommons.org/presskit/icons/by.xlarge.png']
for url in urls:
file_name = url.split("/")[-1:][0]
print(file_name)
file = requests.get(url, verify=False)
open(file_name, 'wb').write(file.content)
cc.xlarge.png
by.xlarge.png
CVE data downloading¶
All CVE IDs are taken from https://www.cve.org/Downloads
[3]:
url = 'https://github.com/CVEProject/cvelistV5/archive/refs/heads/main.zip'
file_name = url.split("/")[-1:][0]
print(file_name)
main.zip
[4]:
import requests
import urllib3
urllib3.disable_warnings()
file = requests.get(url, verify=False)
open(file_name, 'wb').write(file.content)
[4]:
579452546
[5]:
import zipfile
with zipfile.ZipFile(file_name, 'r') as zip_ref:
zip_ref.extractall()
CVE data parsing¶
[6]:
import os
import json
import pandas as pd
base_path = "cvelistV5-main/cves"
rows = []
for item in os.listdir(base_path):
item_path = os.path.join(base_path, item)
if not os.path.isdir(item_path) or not item.isdigit():
continue
year = int(item)
for root, dirs, files in os.walk(item_path):
for file in files:
if file.endswith(".json"):
full_path = os.path.join(root, file)
try:
with open(full_path, "r", encoding="utf-8") as f:
data = json.load(f)
cve_id = data.get("cveMetadata", {}).get("cveId")
if cve_id:
rows.append({"number": cve_id, "year": year})
except Exception as e:
print(f"Failed to parse {full_path}: {e}")
df = pd.DataFrame(rows).sort_values(by="number").reset_index(drop=True)
print(df)
number year
0 CVE-1999-0001 1999
1 CVE-1999-0002 1999
2 CVE-1999-0003 1999
3 CVE-1999-0004 1999
4 CVE-1999-0005 1999
... ... ...
349457 CVE-2026-8235 2026
349458 CVE-2026-8241 2026
349459 CVE-2026-8242 2026
349460 CVE-2026-8243 2026
349461 CVE-2026-8244 2026
[349462 rows x 2 columns]
[7]:
df = df.groupby(['year'], as_index=False)[['number']].count()
df.reset_index(drop=True, inplace=True)
df.index += 1
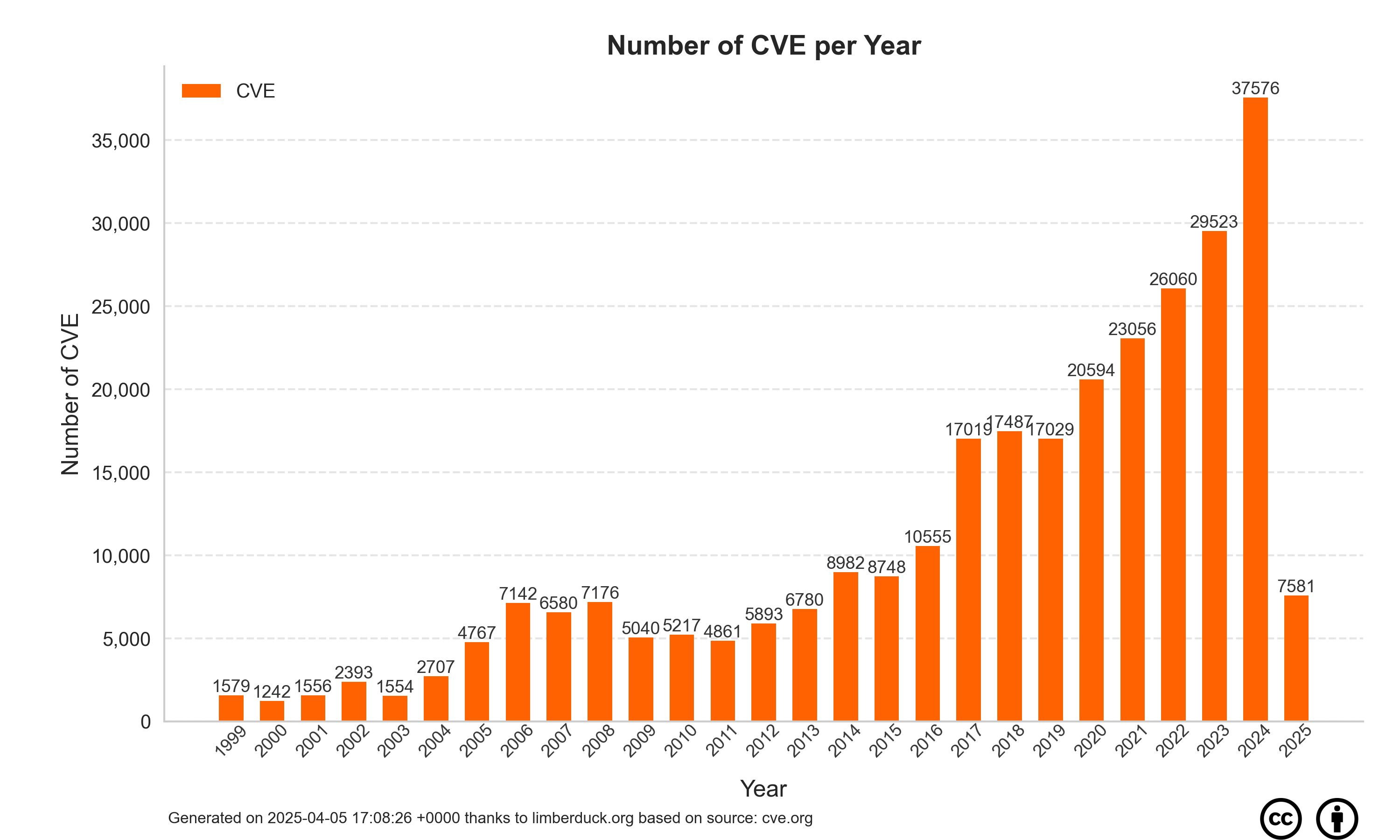
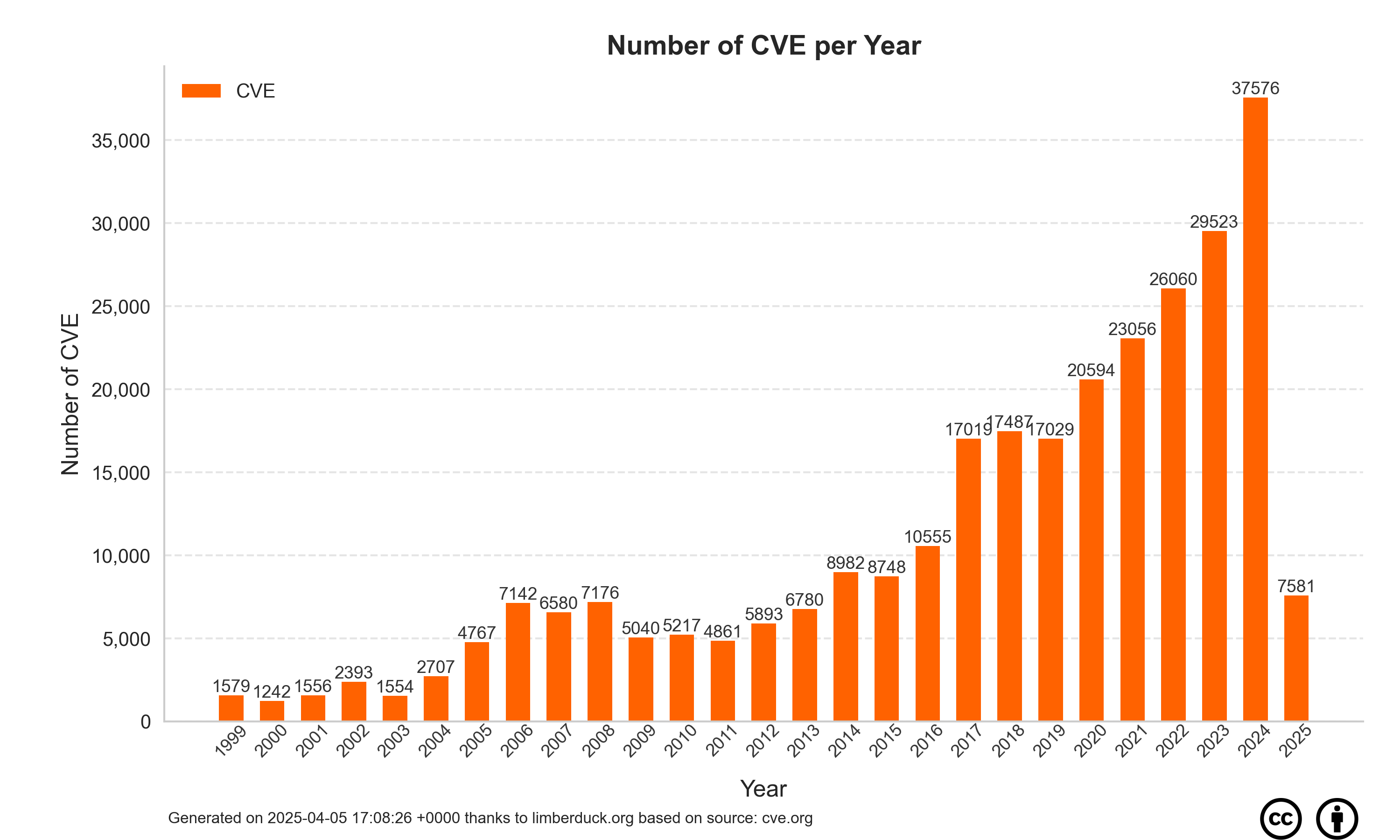
df.style.bar(subset=['number'], color='#FF6200')
[7]:
| year | number | |
|---|---|---|
| 1 | 1999 | 1579 |
| 2 | 2000 | 1243 |
| 3 | 2001 | 1556 |
| 4 | 2002 | 2393 |
| 5 | 2003 | 1555 |
| 6 | 2004 | 2707 |
| 7 | 2005 | 4770 |
| 8 | 2006 | 7145 |
| 9 | 2007 | 6580 |
| 10 | 2008 | 7179 |
| 11 | 2009 | 5053 |
| 12 | 2010 | 5249 |
| 13 | 2011 | 4898 |
| 14 | 2012 | 5939 |
| 15 | 2013 | 6830 |
| 16 | 2014 | 9002 |
| 17 | 2015 | 8779 |
| 18 | 2016 | 10611 |
| 19 | 2017 | 17061 |
| 20 | 2018 | 17698 |
| 21 | 2019 | 17571 |
| 22 | 2020 | 21013 |
| 23 | 2021 | 23389 |
| 24 | 2022 | 27499 |
| 25 | 2023 | 31183 |
| 26 | 2024 | 39078 |
| 27 | 2025 | 44247 |
| 28 | 2026 | 17655 |
CVE data saving¶
CSV file is available in GitHub repository, see:
[8]:
csv_filename = 'cve-number-of-entries.csv'
df.to_csv(csv_filename, index=False)
CVE data ploting¶
PNG files are available in GitHub repository with two background versions, see:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
[9]:
import pandas as pd
import matplotlib.pyplot as plt
import datetime
from matplotlib import ticker
df = pd.read_csv(csv_filename)
# Set style and colors
plt.style.use('seaborn-v0_8-whitegrid')
bar_color = '#FF6200'
# Create figure and axes
fig, ax = plt.subplots()
bars = ax.bar(df['year'], df['number'], color=bar_color, width=0.6)
# Add value labels above bars
for bar in bars:
height = bar.get_height()
ax.text(bar.get_x() + bar.get_width() / 2,
height,
f'{int(height)}',
ha='center', va='bottom',
fontsize=9, fontweight='light', color='#333333')
# Disable default x-axis ticks
ax.set_xticks([])
# Add labels below bars
for bar, label in zip(bars, df['year']):
ax.text(bar.get_x() + bar.get_width() / 2,
0, # baseline
str(label),
ha='center', va='top',
rotation=45,
fontsize=9, color='#333333')
# Labels and title with improved font size
ax.set_xlabel('Year', fontsize=12, labelpad=30)
ax.set_ylabel('Number of CVE', fontsize=12)
ax.set_title('Number of CVE per Year', fontsize=14, fontweight='bold')
# Tweak spines and grid
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.grid(axis='y', linestyle='--', alpha=0.5)
# Format Y-axis with thousands separator
ax.yaxis.set_major_formatter(ticker.FuncFormatter(lambda x, _: f'{int(x):,}'))
plt.tight_layout()
plt.legend(['CVE'])
plt.figtext(0.12, 0.02,
f"Generated on {generation_time} thanks to limberduck.org based on source: cve.org",
ha="left", fontsize=8)
# Figure background
fig.set_size_inches(10, 6)
fig.patch.set_facecolor('white')
# License icons
img_cc = plt.imread('cc.xlarge.png')
newax_cc = fig.add_axes([0.88, 0.0, 0.05, 0.05], anchor='NE', zorder=-1)
newax_cc.imshow(img_cc)
newax_cc.axis('off')
img_by = plt.imread('by.xlarge.png')
newax_by = fig.add_axes([0.92, 0.0, 0.05, 0.05], anchor='NE', zorder=-1)
newax_by.imshow(img_by)
newax_by.axis('off')
# Save images
plt.savefig('cve-number-of-entries-bg-white.png', dpi=300, facecolor='white')
plt.savefig('cve-number-of-entries-bg-transparent.png', dpi=300, transparent=True)
